HuggingChat is an open source alternative for ChatGPT by HuggingFace. With aitomChat we extend the functionality of HuggingChat by enabling you to talk with your documents.
aitomChat is seamlessly integrated into HuggingChat.
Unlike OpenAI’s ChatGPT this solution provides real privacy for your PDFs and other document types. By being able to run locally in an Intranet or Private Cloud it is the ideal solution for companies that want to allow their employees to talk with the company’s data.
Learn everything, from Chat UI to Inference and Retrieval Augmented Generation (RAG) in the YouTube video below:
Learn how you can compose a fully functional LangChain app without writing a single line of code. We demonstrate this live in this YouTube video by utilizing the latest release of our AI automation software aitom8.
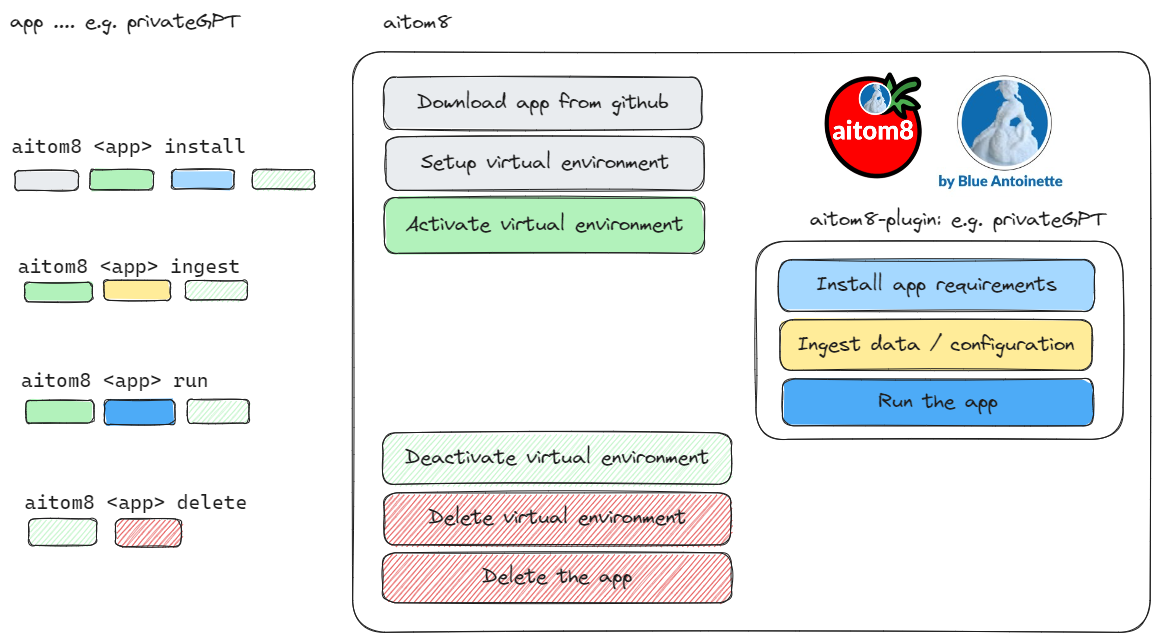
When you run your favorite open source AI apps on your system you usually download the apps from a repository like github, then you install the requirements, then e.g. in the case of privateGPT you ingest the data and then you run the app.
However, all AI apps have different requirement and if you do not want to mess up your system you manually create and activate a virtual environment with conda (or pyenv and venv) before actually installing the app requirements. When you are finished with the app you probably deactivate and maybe delete the virtual environment and the AI app again.
Since this process is very time consuming to perform all these steps manually over and over again, we have developed aitom8 that automates all these steps for you.
Learn more in our YouTube video AI automation with aitom8:
Learn how you can run HuggingChat, an Open Sourced ChatGPT alternative, locally (on a VM) and interact with the Open Assistant model, respectively with any Large Language Model (LLM), in two variants.
Variant 1: Run just the Chat-UI locally and utilize a remote inference endpoint from Hugging Face
Variant 2: Run the whole stack, the Chat-UI, the Text Generation Inference Server and the (Open Assistant) LLM on your Virtual Machine
Installing HuggingChat with the Installation Scripts created in this video
If you want toget the HuggingChat Installation Scripts that we created in the course ofthis video feel free to purchase and download our HuggingChat Installation Scripts.
Alternatively, if you want to get your hands dirty, you find the scripts at the bottom of this page.
NEW! Installing HuggingChat with aitom8 and the HuggingChat aitom8 plugin
New: In the meanwhile we have created aitom8 which is a professional AI Automationsoftware that automates a variety of open source projects (optionally in virtual environments like conda). For HuggingChat there is an aitom8 plugin available that allows you to install HuggingChat with just one command.